

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpaUkpxy
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
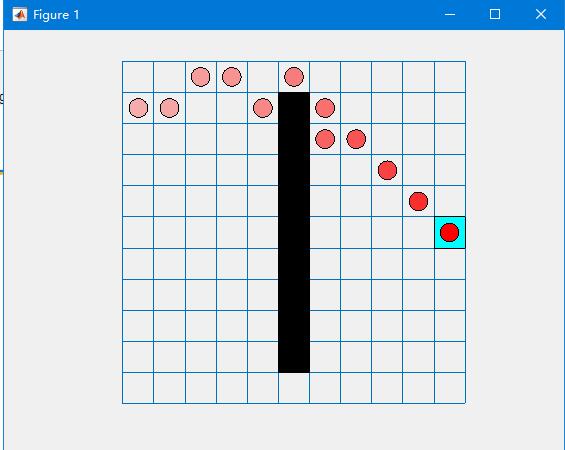
2.部分仿真图预览
3.算法概述
Q-Learning是强化学习中的一种重要算法,它属于无模型(model-free)学习方法,能够使智能体在未知环境中学习最优策略,无需环境的具体模型。将Q-Learning应用于路线规划和避障策略中,智能体(如机器人)能够在动态变化的环境中,自主地探索并找到从起点到终点的最安全路径,同时避开障碍物。
4.部分源码
%创建Q学习智能体
% 首先,根据环境的观察和动作规范创建Q表
Qtab = rlTable(getObservationInfo(Envir),getActionInfo(Envir));
% 创建表型表示并设置学习率为0.5
Reptab = rlRepresentation(Qtab);
Reptab.Options.LearnRate = 0.5;
% 接着,使用此表型表示创建Q学习智能体,并配置epsilon贪心策略
agentOpts = rlQAgentOptions;
agentOpts.EpsilonGreedyExploration.Epsilon = 0.04;
qAgent = rlQAgent(Reptab,agentOpts);
%训练Q学习智能体
trainOpts = rlTrainingOptions;
trainOpts.MaxStepsPerEpisode = 100;% 每个episode最大步数
trainOpts.MaxEpisodes = 400;% 总训练episode数
trainOpts.StopTrainingCriteria = "AverageReward";% 停止训练的条件
trainOpts.StopTrainingValue = 40;% 达到的平均奖励阈值
trainOpts.ScoreAveragingWindowLength = 30;% 平均奖励的窗口长度
% 开始训练智能体
trainingStats = train(qAgent,Envir,trainOpts);
0Z_003m
---