

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpWZm55v
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
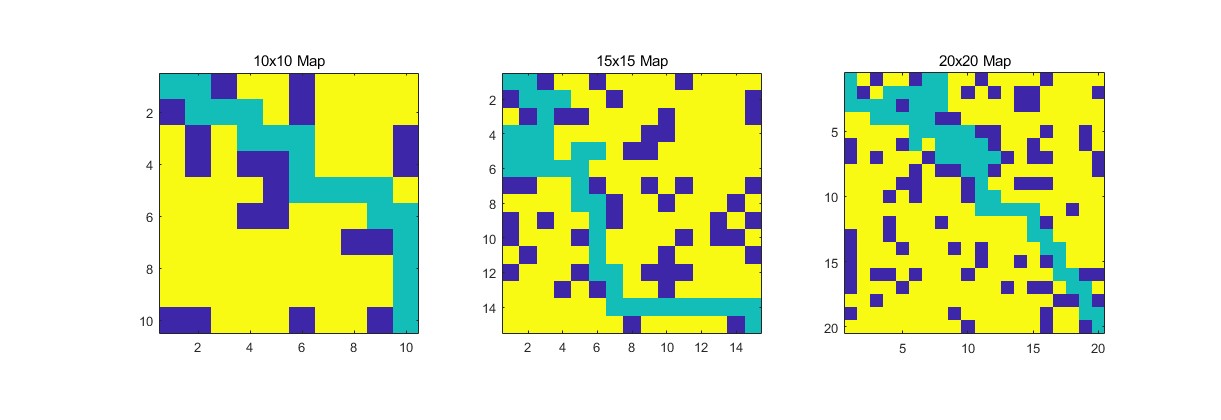
2.部分仿真图预览
3.算法概述
Q-Learning是强化学习中的一种重要算法,它属于无模型(model-free)学习方法,能够使智能体在未知环境中学习最优策略,无需环境的具体模型。将Q-Learning应用于路线规划和避障策略中,智能体(如机器人)能够在动态变化的环境中,自主地探索并找到从起点到终点的最安全路径,同时避开障碍物。
4.部分源码
........................................................
% 开始迭代
tic;
for ij = 1 : Epoch %Iterasyonlar baslasin.
while true
% 如果到达目标状态,退出循环
if State_cur == scale*scale
break
end
% 选择当前状态下的最优动作
[next,action]= max(Qmat(State_cur, :));
% 计算下一状态的坐标
State_next = State_cur + Cact(action);
[x,y] = func_state10(State_next,scale);
if State_next == StateG
Reward = 20;
elseif Map(x,y) == 0
Reward = -10;
else
Reward = -1;
end
% 更新 Q 矩阵
[a,b] = func_state10(State_cur, scale);
% 更新 Q 矩阵
Qmat(State_cur,action) = Qmat(State_cur,action) + Rl*(Reward + Rd * max(Qmat(State_next, :))-Qmat(State_cur,action));
end
% 显示每次迭代访问的状态数
llrq(ij)=length(State_set);
end
times=toc;
% 显示最后的路径
for i=1:length(State_set)
[a,b] = func_state10(State_set(i),scale);
Map(a,b)= 0.5;% 路径上的格子显示为灰色
end
figure;
imagesc(Map);
drawnow;
figure;
plot(llrq);
xlabel('迭代次数');
ylabel('访问状态数');
save Q10.mat times Map llrq
0Z_002m
---