

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Z52alJ1u
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
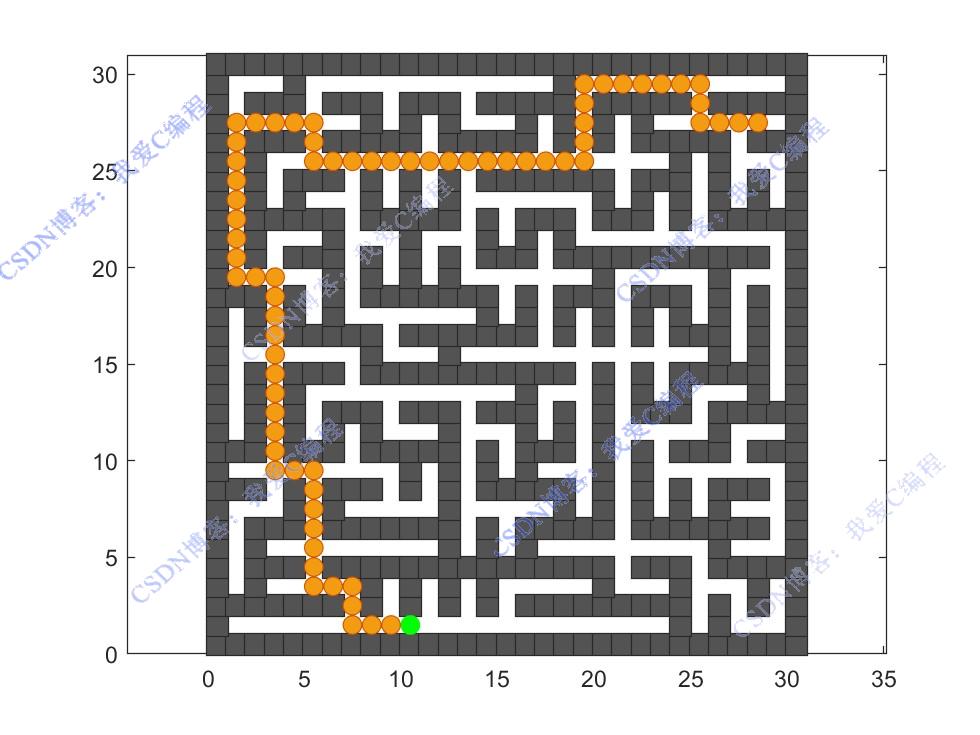
2.部分仿真图预览
3.算法概述
经过多轮训练后,Q 表已经学习到了不同状态下较优的动作策略。在实际路线搜索时,将机器人置于起点状态,然后在每一个状态下,直接选择 Q 值最大的动作(即采用贪婪策略,不再有探索概率 ),机器人按照选择的动作依次移动,直至到达终点,所经过的路径即为搜索到的最优路线(在 Q 表学习足够好的情况下,近似最优)。
4.部分源码
.............................................................
Rwd_all = [];
Q2_all = [];
for i=1:Episodes
i
[total_reward,Q,Model,Info,Q2]= func_episode(Q,Model,Miters) ;
Rwd_all= [Rwd_all,total_reward];
Q2_all = [Q2_all,mean(Q2)];
end
figure;
plot(Rwd_all,'b-o');
xlabel('训练次数');
ylabel('累计奖励值');
figure;
plot(Q2_all,'b-o');
xlabel('训练次数');
ylabel('Q值');
[x]=Info{1};
[Maps2]=Info{2};
[Mapsv2]=Info{3};
[Q]=Info{4};
[N,M] = size(Maps2);
figure;
[Rms,Cms] = find(Maps2);
plot(Rms-0.5,Cms-0.5,'s','MarkerEdgeColor', '#29292a' ,'MarkerFaceColor','#535353','MarkerSize',12);
hold on;
xlim(gca,[0 N]);
ylim(gca,[0 M]);
box(gca,'on');
axis equal
plot(XY0(1)+0.5,XY0(2)+0.5,'og','MarkerFaceColor','g','MarkerSize',8);
plot(x(1)+0.5,x(2)+0.5,'sr','MarkerFaceColor','r','MarkerSize',8);
hold off;
figure;
[Rms,Cms] = find(Maps2);
plot(Rms-0.5,Cms-0.5,'s','MarkerEdgeColor', '#29292a' ,'MarkerFaceColor','#535353','MarkerSize',12);
hold on;
xlim(gca,[0 N]);
ylim(gca,[0 M]);
box(gca,'on');
axis equal
plot(XY0(1)+0.5,XY0(2)+0.5,'og','MarkerFaceColor','g','MarkerSize',8);
plot(x(1)+0.5,x(2)+0.5,'sr','MarkerFaceColor','r','MarkerSize',8);
[mx,my] = find(Mapsv2);
plot(mx-0.5,my-0.5,'o','MarkerEdgeColor', '#d35400' ,'MarkerFaceColor',' #f39c12 ','MarkerSize',8);
hold off;
0Z_013m
---