

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Z5iYmJly
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
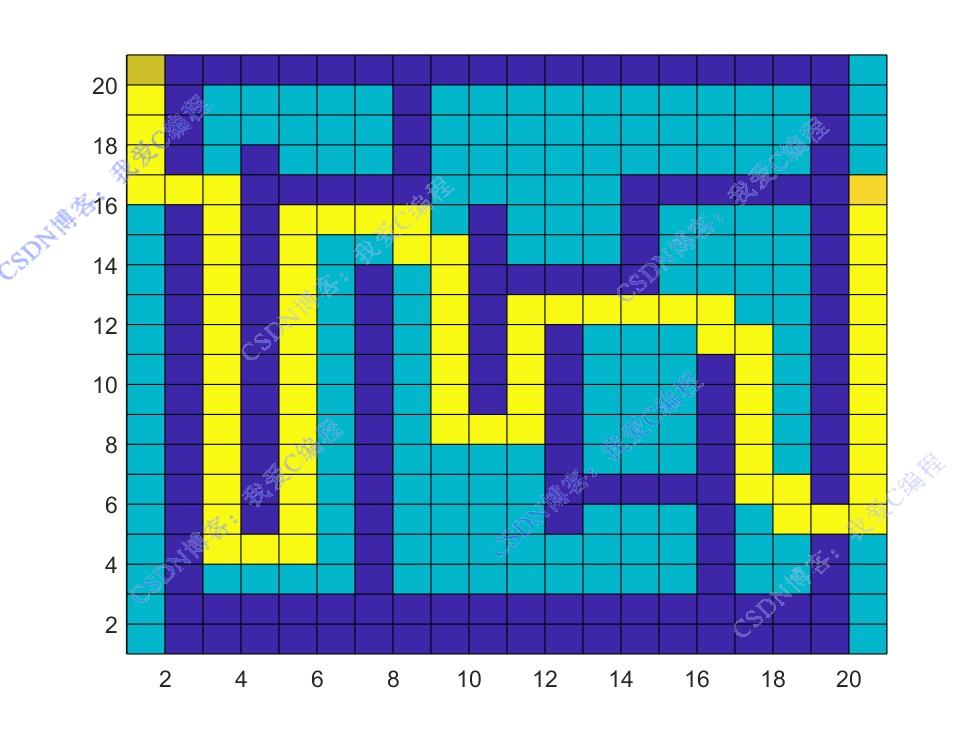
2.部分仿真图预览
3.算法概述
强化学习是机器学习中的一个领域,强调智能体(agent)如何在环境(environment)中采取一系列行动(action),以最大化累积奖励(reward)。智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优的行为策略。在机器人导航中,状态可以是机器人的位置和姿态,动作可以是不同的运动指令(如前进、后退、转弯等),奖励可以根据机器人是否接近目标位置或者避开障碍物来设定。通过 Q - Learning,机器人可以学习到从初始位置到目标位置的最优路径规划策略。在机器人路径规划问题中,机器人即为智能体,其所处的大规模栅格地图及相关物理规则等构成了环境 。智能体通过传感器感知环境的状态,并根据学习到的策略在环境中执行动作,如向上、向下、向左、向右移动等,环境则根据智能体的动作反馈相应的奖励信号和新的状态。
4.部分源码
..........................................................................
% 将效用值和状态的配对按照效用值从小到大的顺序进行排序
Idx_state = [1:nstates]';
% 使用sortrows函数对由效用值U和状态索引estados组成的矩阵按照第一列(即效用值)进行排序
Idxss = sortrows([U Idx_state],1);
Idx_global= [Idx_state,p];
% 获取所有状态在网格上的全局策略
Mat_global= flipdim(reshape(Idx_global(:,2),[Rw1 Cm1]),1);
%输出动作
Action_set = ['上','右','下','左'];
Action_idx = sub2ind(size(Ter1{1}),XY0(1),XY0(2));
Ends = sub2ind(size(Ter1{1}),XY1(1),XY1(2));
Policys = [];% 初始化用于存储策略序列
Action_idx_set = [Action_idx];
while Action_idx~=Ends
if Action_idx~=find(obstacle==1)
% 获取当前状态下的最优策略p
[c1,c2]=ind2sub([Rw1 Cm1],Action_idx);
pop=p(Action_idx);
Action_idx=Ter1{pop}(c1,c2);
% 将本次选择的最优策略添加到策略序列Policys中
Policys = [Policys pop];
Action_idx_set = [Action_idx_set;Action_idx];
end
end
clc;
% 根据策略序列Policys获取对应的动作序列
disp('机器人行驶动作序列:');
Action_seqs = Action_set(Policys)
figure
% 初始化用于存储坐标序列
Posxy = [];
% 创建一个与网格世界维度相同的全零矩阵
Mats1 = zeros(Rw1,Cm1);
% 创建一个与障碍物矩阵obstacle维度相同的矩阵
Mats2 =-75*obstacle;
[Rc11,Cw11] = find(Maps==-1);
J5 = 1;
% 遍历状态序列每个状态索引
for i=1:length(Action_idx_set)
% 根据状态索引Action_idx_set计算其在网格世界中的行坐标c1和列坐标c2
[c1,c2] = ind2sub([Rw1 Cm1],Action_idx_set(i));
% 将当前状态的坐标添加到坐标序列
Posxy = [Posxy;[c1 c2]];
Mats1(end+1-c1,c2)= J5;
Mats2(c1,c2) = 90;
J5=J5+1;
end
Mats2(XY0(1),XY0(2))=50;
Mats2(XY1(1),XY1(2))=75;
Mats2(Rc11,Cw11) =65;
Map_line=[[flipdim(Mats2,1) zeros(Rw1,1)];zeros(1,Cm1+1)];
pcolor(Map_line)
% title(['机器人行驶路线:',Action_seqs]);
0Z_011m
---