

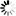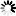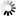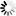
1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpmYmp9r
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
3.算法概述
强化学习是一种机器学习方法,它使智能体能够在与环境交互的过程中学习如何采取行动以最大化累积奖励。Q-Learning是一种无模型的强化学习算法,特别适合于离散动作空间的问题。在机器人避障和路径规划中,Q-Learning可以帮助机器人学习如何在未知环境中寻找到达目标的最短路径,同时避免碰撞障碍物。
4.部分源码
..................................................................
% 更新Q表
Qtab(Start_randm,Acts_temp) = (1-Lrr)*Qtab(Start_randm,Acts_temp) + Lrr*(Rwd + gamma * Nmax);
% 更新状态
Start_randm = s_n;
% 可视化新状态
xx = ceil(Start_randm/Scales);
yy = Start_randm - (xx-1)*Scales;
Env_cur = Map_mat;
Env_cur(xx,yy) = 4;
if mod(m,100)==1
imagesc(Env_cur);
end
m = m + 1;
if m > Lmv
flager2 = 0;
end
if Start_randm == Goal
flager2 = 0;
end
end
% 绘制Q表均值变化图
figure;
plot(epsilon2);
xlabel('训练迭代次数');
ylabel('Q收敛值');
% 保存数据
save data.mat Env Qtab Start0
0Z_008m
---