

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Z5ycmJpx
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
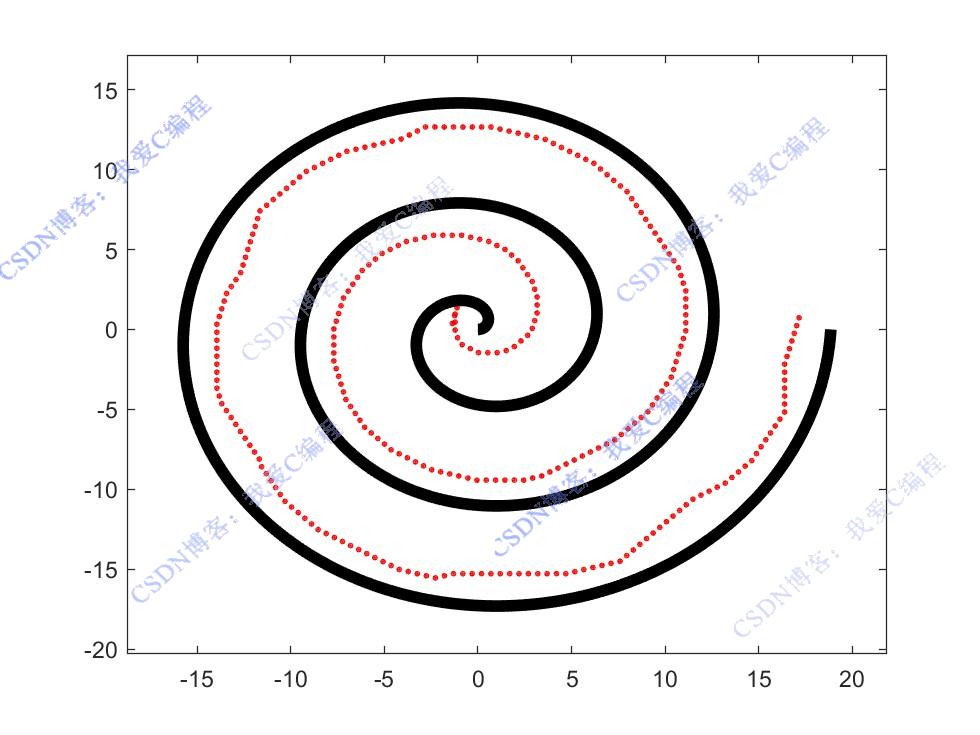
2.部分仿真图预览
3.算法概述
强化学习是机器学习中的一个重要领域,它主要研究智能体(agent)如何在环境中通过不断地试错来学习最优策略(policy),以最大化长期累积奖励(reward)。在机器人路线规划问题中,机器人即为智能体,其所处的地图环境包含了起点、终点、障碍物等元素,机器人的目标是找到一条从起点到终点的最优路径,同时避免碰撞障碍物。
4.部分源码
...............................................................
for i=1:Epechs
if Emg==1
a=4; % 如果处于紧急情况(emergency为1),则将动作a设置为4,从代码逻辑推测动作4可能代表向后退的动作(具体含义要结合整体代码设定来看),目的是在遇到紧急情况(比如距离障碍物过近等)时,智能体采取向后退的操作来避免碰撞,保证探索过程的安全性
else% 如果不处于紧急情况(emergency为0),则进入以下分支进行动作选择操作,根据epsilon - 贪婪策略来决定是选择当前已知的最优动作还是随机选择一个动作。
if rand<(1-epsilon)% 如果生成的随机数(rand函数会生成一个在0到1之间的均匀分布随机数)小于 (1 - epsilon),说明按照概率应该选择当前已知的最优动作,此时调用max函数找到动作价值矩阵Q中当前状态s_index对应的行(即当前状态下执行不同动作的价值估计值所在行)中的最大值以及其对应的列索引,将最大值对应的列索引赋值给动作变量a,即选择当前状态下价值估计最高的动作作为要执行的动作,这体现了利用已知最优策略的部分
[q,a] = max(Q(State_idx,:));
else% 如果生成的随机数大于等于 (1 - epsilon),说明按照概率应该随机选择一个动作,此时调用randi函数在动作数量范围(1到Nactions)内随机生成一个整数,将其赋值给动作变量a,即随机选择一个可执行的动作,这体现了探索新动作的部分
a=randi(Nactions);
end
end
% 执行选择的动作并到达下一个状态,以下代码调用func_env函数,传入选择的动作a、当前状态s、状态类型type、当前位置location、迷宫坐标信息maze_coordinates、临界距离critical_distance以及紧急距离emergency_distance作为参数,获取的返回值分别赋值给agent_next_location、reward、next_s_type、next_state、terminal、emergency变量,用于实现智能体执行动作后的位置更新(agent_next_location)、获取执行动作后的奖励值(reward)、确定下一个状态的类型(next_s_type)、下一个状态向量(next_state)、判断是否达到终止状态(terminal)以及是否处于紧急情况(emergency)等操作,完成一次动作执行后的状态转移和相关信息更新
[Loc_next,reward,tp_next,state_next,Ends,Emg]=func_env(a,s,type,location,Mapxy,distc,diste);
% 更新用于绘制的智能体原点轨迹信息,每执行一次动作到达新位置后,将索引变量j的值加1,然后将智能体新位置agent_next_location中第一个点(即原点)的坐标赋值给轨迹数组trajectory的第j行,以此记录智能体在探索过程中原点位置的变化轨迹,方便后续可视化展示智能体的移动路径情况
j=j+1;
% 调用func_stateidx函数,传入下一个状态向量next_state以及下一个状态的类型next_s_type作为参数,获取的返回值赋值给s_index_next变量,用于确定下一个状态在Q矩阵中的索引,方便后续基于该索引对动作价值矩阵Q进行更新操作,保持状态与价值估计信息的对应关系
idx_next=func_stateidx(state_next,tp_next);
if a~=4
% 如果执行的动作不是紧急情况对应的动作(即不是动作4,从前面代码可知动作4可能代表向后退的紧急动作),说明是正常的探索动作,执行以下更新动作价值矩阵Q的操作,通过基于当前奖励值reward、折扣因子gamma以及下一个状态的最大价值估计值(通过max(Q
Q(State_idx,a)=Q(State_idx,a)+alpha*(reward+gamma*max(Q(idx_next,:))-Q(State_idx,a));
end
%更新状态
s = state_next;
location = Loc_next;
type = tp_next;
State_idx= idx_next;
if i==Epechs
figure(2)
[Mapxy]=func_Map();
plot(location(1,1),location(1,2),'r-o','MarkerSize',2);
hold on
end
end
end
0Z_012m
---