

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpeXm5xr
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
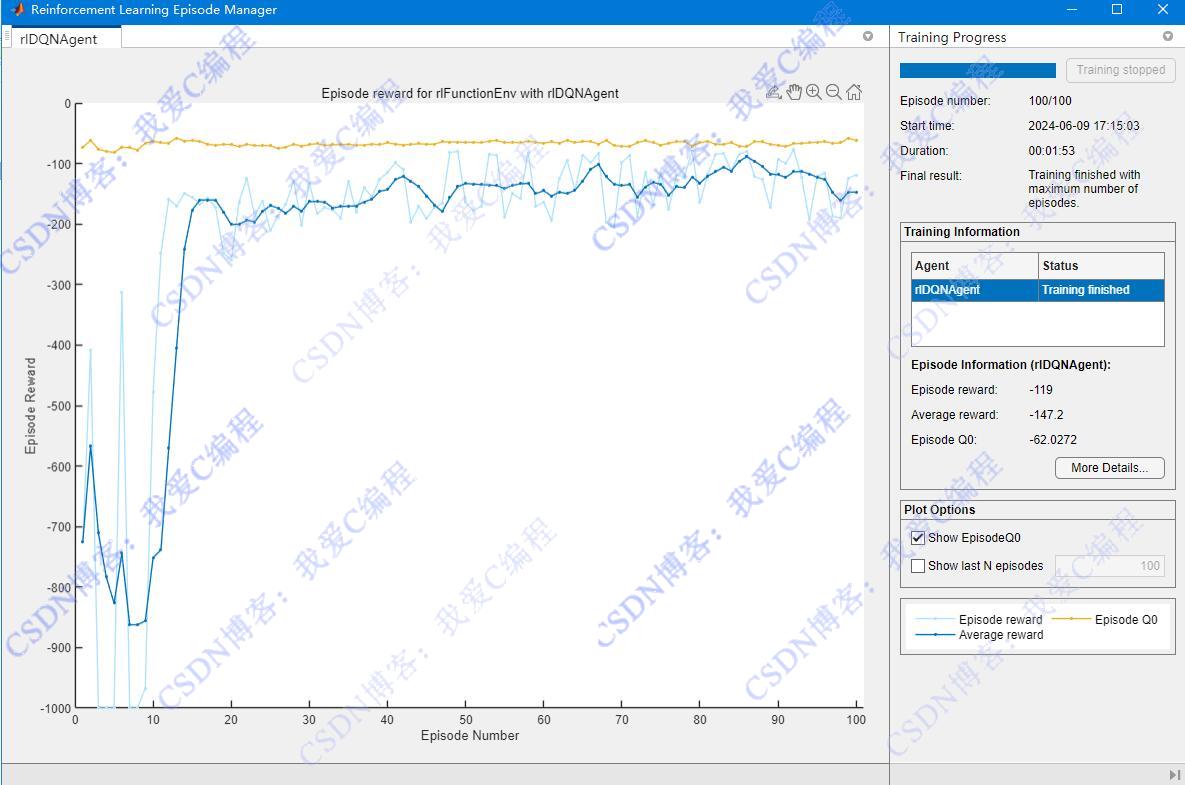
3.算法概述
Q-learning是一种离散时间强化学习算法,无需模型即可直接从环境中学习最优策略。当应用于小车弧线轨迹行驶控制时,其核心任务是让小车自主学习如何控制转向和速度,以在指定的曲线上稳定行驶。
4.部分源码
............................................................
figure;
for i = 1:length(ysim.Reward.Time)
cla;
plot(Xpos,Ypos,'b');
hold on
x = States(1,1,i);
y = sin(5*x);
plot(x,y,'sq','MarkerSize',10,'MarkerEdgeColor','red','MarkerFaceColor',[0 1 0]);
title(['Reward = ' num2str(crwd(i))])
pause(0.025)
end
% 绘制结果
figure;
plot(Tnets.EpisodeIndex,Tnets.EpisodeReward,'b');
hold on;
plot(Tnets.EpisodeIndex,Tnets.AverageReward,'r');
xlabel('训练次数');
ylabel('奖励');
legend('训练奖励','平均奖励');
0Z_005m
---