

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpaZl5dq
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
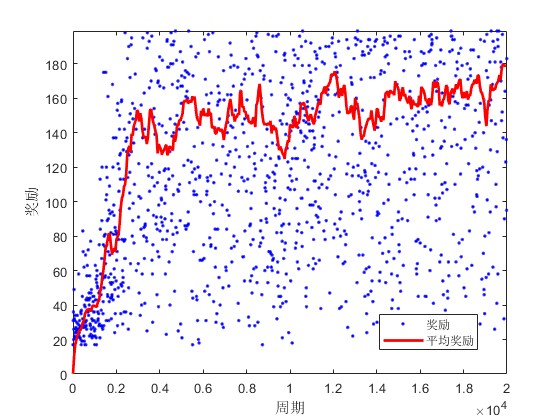
3.算法概述
基于Q-learning的强化学习方法应用于小车倒立摆控制系统,是通过让智能体(即控制小车的算法)在与环境的交互过程中学习到最优的控制策略,以保持倒立摆在不稳定平衡状态下的直立。Q-learning作为一种无模型的强化学习算法,特别适合解决这类动态环境下的决策问题。
4.部分源码
。。。。。。........................................................% 时间步循环
for t = 1:Times
t
% 更新j
idj = NewState;
% 策略:使用贪婪方法定义动作
[~,idi] = max(Qtable(idj,:));
A = action(idi);
% 更新状态
[State,Reward,~] = func_model(State,A);
% 量化连续状态以提取下一个状态索引
NewState = func_idx(State,Cars); % extract state index
ha = gca(h2);
%车位置和杆角度
x = State(1);
theta = State(3);
Car_show1 = findobj(ha,'Tag','Car_show1');
Car_show2 = findobj(ha,'Tag','Car_show2');
% 更新车和杆的位置
[Xcar,~] = centroid(Car1);
[Xp,Yp] = centroid(Car_show3);
dx = x - Xcar;
thetad = theta - atan2(Xcar-Xp,Yp-0.25/2);
Car1 = translate(Car1,[dx,0]);
Car_show3 = translate(Car_show3,[dx,0]);
Car_show3 = rotate(Car_show3,rad2deg(thetad),[x,0.25/2]);
Car_show1.Shape = Car1;
Car_show2.Shape = Car_show3;
pause(0.02)
end
0Z_004m
---