

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/ZpqamZZr
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
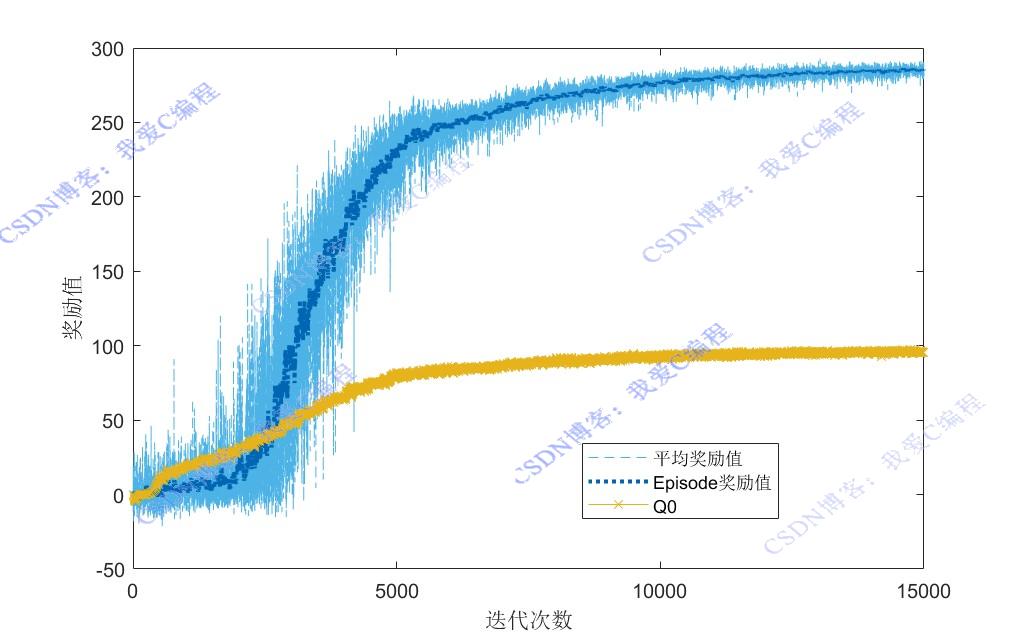
3.算法概述
基于Actor-Critic强化学习的四旋翼无人机飞行控制系统是一种利用强化学习技术实现飞行器自主控制的方法。该方法通过构建Actor(策略网络)和Critic(价值网络)两个组件来学习最优控制策略。四旋翼无人机因其灵活性和广泛应用前景成为研究热点。传统的控制方法依赖于精确的数学建模和控制律设计,但在复杂和不确定环境下表现有限。
4.部分源码
........................................................................
% 加载已训练好的代理
load trained\ac.mat
opts = rlSimulationOptions('MaxSteps',(Time2-Time1)/dt);% 设置最大步骤数
Rwd_all = zeros(Sim_times,1);% 初始化总奖励数组
Steps_all = zeros(Sim_times,1);% 初始化步数数组
for i = 1:Sim_times% 对于每次模拟
Exp_learn = sim(Environment,agent,opts);% 运行模拟并获取经验
Rwd_all(i) = sum(Exp_learn.Reward);% 计算并存储总奖励
end
figure;
plot(Rwd_all,'-bs',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.4,0.9,0.4]);
xlabel('仿真次数');
ylabel('奖励值');
ylim([200,300])
% 提取模拟中的位置数据
Xs = Exp_learn.Observation.Quad.Data(1,:);% 获取X方向位移
Ys = Exp_learn.Observation.Quad.Data(2,:);% 获取Y方向位移
Zs = Exp_learn.Observation.Quad.Data(3,:);% 获取Z方向位移
dist = sqrt((Xs).^2 + (Ys).^2 + (Zs).^2);
figure
subplot(1,2,1)
plot3(Xs,Ys,Zs,'-b',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.0,0.0]);
grid on
xlabel('X')
ylabel('Y')
zlabel('Z')
title('无人机三维飞行轨迹');
subplot(1,2,2)
plot(dist)
xlabel('Time (s)')
ylabel('距离')
0Z_009m
---