

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Z56bm51t
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
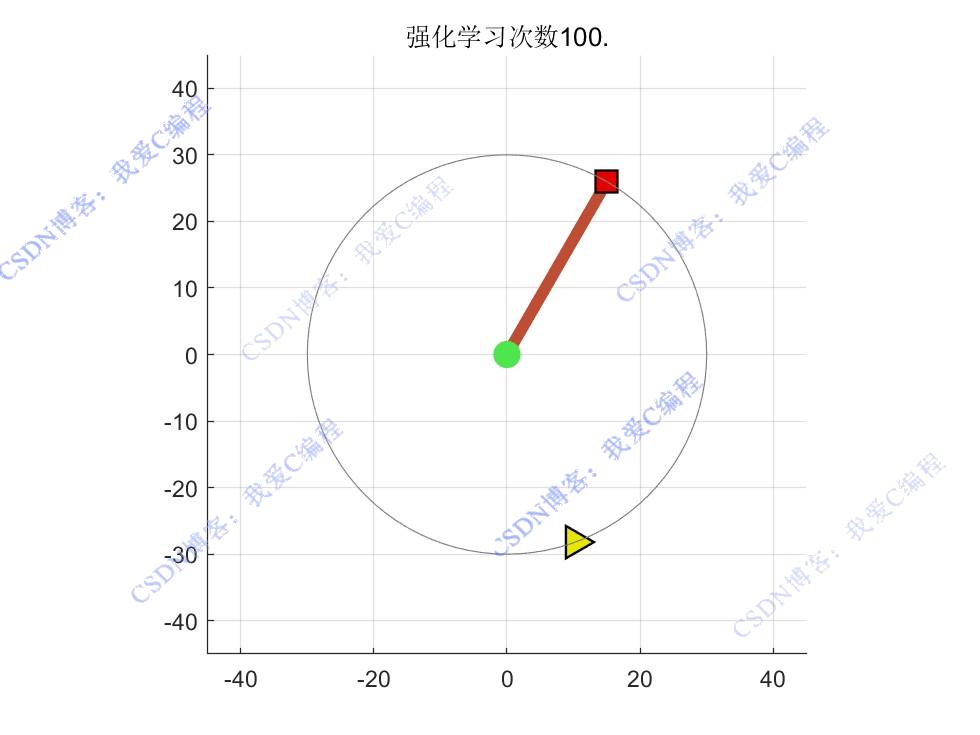
3.算法概述
强化学习作为一种无模型的学习方法,通过智能体与环境进行交互,不断尝试不同的动作并根据环境反馈的奖励来学习最优策略,能够在不确定环境中实现高效的决策和控制。Q-learning 是一种经典的强化学习算法,它通过学习一个动作价值函数(Q 函数)来确定最优策略,具有实现简单、收敛性好等优点。因此,将 Q-learning 算法应用于1DoF机械臂运动控制中,能够有效提高机械臂在复杂环境下的适应性和控制性能。
4.部分源码
.........................................................................
% 定义学习率,用于在更新Q矩阵时权衡新旧值的权重
Lr = 0.99;
% 初始的探索概率
Epsr = 1;
% 每次迭代的探索概率衰减因子
Rdec = 0.9999;
% 初始化当前的探索概率
Pes = Epsr;
%在评估状态和动作的价值时,考虑未来状态价值的重要性
dcnt = 0.3;
% 定义成功执行预期动作的概率
Su_rate = 1;
% 当系统到达期望状态(摆锤直立)时给予的巨大奖励
Rewardr = 1000000;
.........................................................................
% 初始化一个长度为 Miter 的零向量,用于存储每个回合的平均奖励
Rwdm = zeros(1,Miter);
Action_set0= zeros(1,Mact);
Action_set = zeros(1,Miter);
% 计算当前回合的平均奖励
Rwd_avg = Rwd_sum/Rwd_cnt;
% 将当前回合的平均奖励存储到 Rwdm 向量中
Rwdm(ij) = Rwd_avg;
Action_set(ij) = mean(Action_set0);
end
% 创建一个新的图形窗口
figure
plot(1:Miter, Rwdm,'-r>',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
hold on
xlabel('Epoch');
ylabel('奖励值');
figure
plot(1:Miter, Action_set,'-r>',...
'LineWidth',1,...
'MarkerSize',6,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9,0.9,0.0]);
hold on
xlabel('Epoch');
ylabel('动作值');
0Z_014m
---