

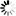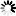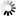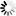
核心提示:A0006,包括程序操作录像...
1.完整项目描述和程序获取
面包多安全交易平台:https://mbd.pub/o/bread/Y5uVl5pw
如果链接失效,程序调试报错或者项目合作可以加微信或者QQ联系。
2.部分源码

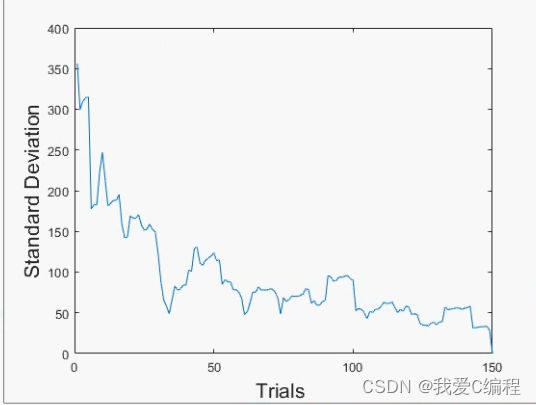
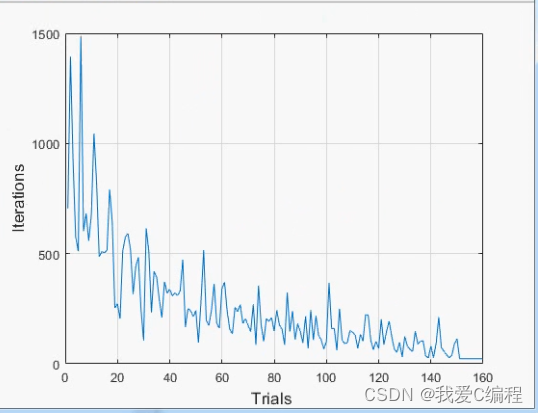
3.部分仿真图预览
4.算法概述
①强化学习是做出最佳决策的科学。它可以帮助我们制定活的物种所表现出的奖励动机行为。比方说,你想让一个孩子坐下来学习考试。要做到这一点非常困难,但是如果每次完成一章/主题时都给他一块巧克力,他就会明白,如果他继续学习,他会得到更多的巧克力棒。所以他会有一些学习考试的动机。
②孩子代表着Agent代理 。奖励制度和考试代表了Environment环境。今天的题目是类似于强化学习的States状态。所以,孩子必须决定哪些话题更重要(即计算每种行为的价值)。这将是我们的工作的 Value-Function价值方程。所以,每次他从一个国家到另一个国家旅行时,他都会得到Reward奖励,他用来在时间内完成主题的方法就是我们的Policy决策。
Q-Learning它是强化学习中的一种 values-based 算法,是以QTable表格形式体现,在学习中遇到的任何操作存入QTable中,根据之前的学习选择当前最优操作,也可以根据设置的e_greedy机率随机选择。