

1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Y5uak5xu
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分源码

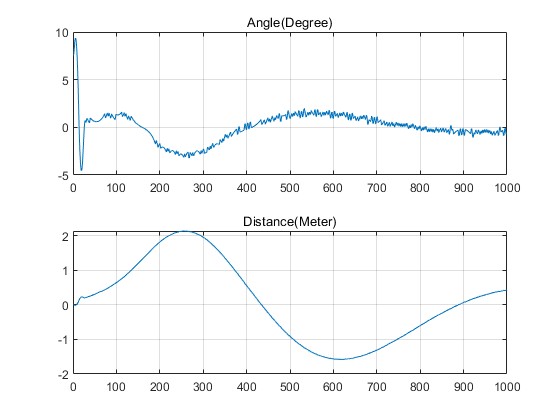
3.部分仿真图预览
4.算法概述
强化学习通常包括两个实体agent和environment。两个实体的交互如下,在environment的statestst下,agent采取actionatat进而得到rewardrtrt 并进入statest+1st+1。Q-learning的核心是Q-table。Q-table的行和列分别表示state和action的值,Q-table的值Q(s,a)Q(s,a)衡量当前states采取actiona到底有多好。
在每一时刻,智能体观测环境的当下状态并选择一个动作,这会导致环境转移到一个新的状态,与此同时环境会返回给智能体一个奖励,该奖励反映了动作所导致的结果。在倒立摆任务中,每一个时间步的奖励均为+1,但是一旦小车偏离中心超过4.8个单位或者杆的倾斜超过15度,任务就会终止。因此,我们的目标是使得该任务能够尽可能地运行得更久,以便获得更多的收益。原始倒立摆任务中,智能体的输入包含4个实数(位置,速度等),但实际上,神经网络可以直接通过观察场景来完成任务,所以我们可以直接使用以小车为中心的屏幕补丁作为输入。严格来说,我们设计的状态是当前屏幕补丁与上一个屏幕补丁的差值,这使得智能体能够从一张图像中推断出杆的速度。
为了训练DQN,我们将使用经验回放池(experience replay memory)来存储智能体所观测到的环境状态转移情况,在之后的训练中我们可以充分利用这些数据。通过对经验回放池中的数据进行随机采样,组成一个批次的转移情况是互不相关(decorrelated)的,这极大地提升了DQN训练的性能和稳定性。
主要步骤如下:
采样得到一个批次的样本,将这些样本对应的张量连接成一个单独的张量;
分别利用策略Q网络与目标Q网络计算 与Q(st,at)与V(st+1)=maxaQ(st+1,a) ,利用它们计算损失函数.。另外,如果 s 为终止状态,则令 V(s)=0
更新Q网络参数。目标Q网络的参数每隔一段时间从主Q网络处固定而来,在本例中,我们在每个episode更新一次目标Q网络。