

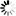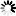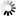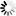
1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Y52bl5ly
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
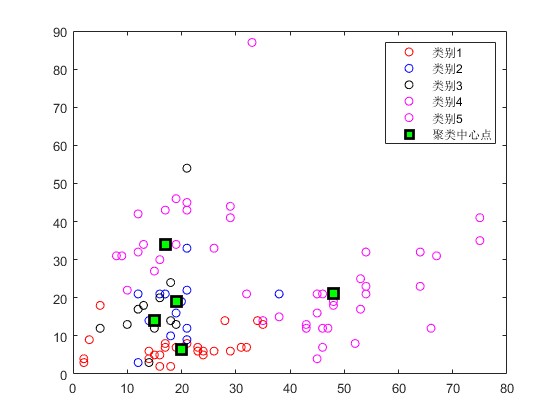
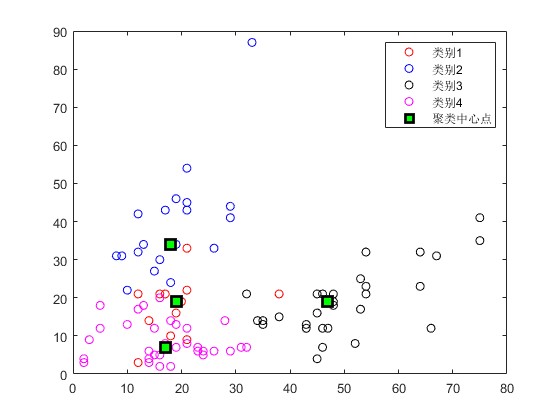
3.算法概述
首先计算整个数据集合的平均值点,作为第一个初始聚类中心C1;
然后分别计算所有对象到C1的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W。
此时计算P=u*d+(1-u)*W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C2。
同样的方法,分别计算所有对象到C2的欧式距离d,并且计算每个对象在半径R的范围内包含的对象个数W,所得到的最大的P值所对应的的对象作为第二个初始聚类中心C3。
从这三个初始聚类中心开始聚类划分。对于一个待分类的对象,计算它到现有聚类中心的距离,若(这个距离)<(现有各个聚类中心距离的最小值),则将这个待分类对象分到与它相距最近的那一类;如果(这个距离)>(现有各个聚类中心距离的最小值),则这个待分类对象就自成一类,成为一个新的聚类中心,然后对所有对象重新归类。
如果找到新的聚类中心,在重新计算聚类的中心后。对目前形成的K+1 个聚类计算 DBInew 的值,和未重新分配对象到这 k+1 个类之前计算的 DBIold进行比较,如果 DBInew <DBIold,则这个新找到的聚类中心可以作为新的聚类中心,否则将终止本次查找 k 的工作,并恢复到 DBIold 的状态。当所有这样符合新类产生条件的数据对象的 DBI 值都大于 DBIold 时,则确定再没有新的类产生,则确定了最终聚类个数为 k,可以进行最终的分配对象工作。
4.部分源码
Dat = xlsread('data.xls');
Feature = zeros(size(Dat));
Feature(:,2:end) = Dat(:,2:end);
KCluster = 6;
X = Feature(:,2:end);
cidx = func_cmeans(X',KCluster);
Feature(:,1) = cidx';
%计算五列重的权值最大的两个
W = mean(X,1);
[V,I] = sort(W);
%选择权值最大的两个进行画图
K1=I(end);
K2=I(end-1);
figure;
plot(X(cidx==1,K1),X(cidx==1,K2),'ro', ...
X(cidx==2,K1),X(cidx==2,K2),'bo', ...
X(cidx==3,K1),X(cidx==3,K2),'ko', ...
X(cidx==4,K1),X(cidx==4,K2),'mo', ...
X(cidx==5,K1),X(cidx==5,K2),'mo', ...
X(cidx==6,K1),X(cidx==6,K2),'co');
hold on;
if KCluster == 2
legend('类别1','类别2','聚类中心点');
end
if KCluster == 3
legend('类别1','类别2','类别3','聚类中心点');
end
if KCluster == 4
legend('类别1','类别2','类别3','类别4','聚类中心点');
end
if KCluster == 5
legend('类别1','类别2','类别3','类别4','类别5','聚类中心点');
end
if KCluster == 6
legend('类别1','类别2','类别3','类别4','类别5','类别6','聚类中心点');
end
05_027_m