

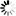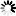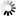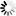
1.完整项目描述和程序获取
>面包多安全交易平台:https://mbd.pub/o/bread/Y5mam5tu
>如果链接失效,可以直接打开本站店铺搜索相关店铺:
>如果链接失效,程序调试报错或者项目合作也可以加微信或者QQ联系。
2.部分仿真图预览
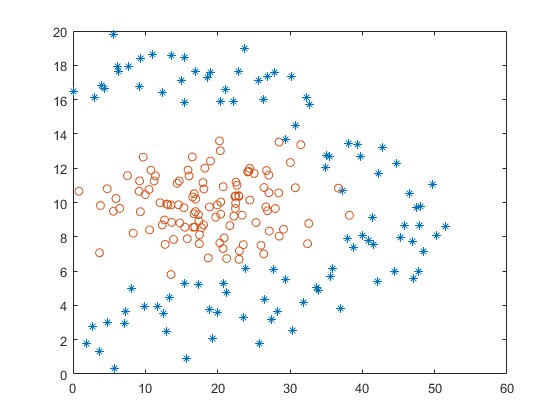
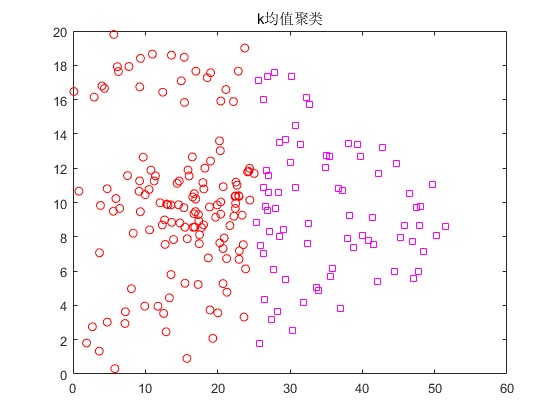
3.算法概述
聚类算法也许是机器学习中“新算法”出现最多、最快的领域,一个重要的原因是聚类不存在客观标准,给定数据集总能从某个角度找到以往算法未覆盖的某种标准从而设计出新算法。Kmeans算法十分简单易懂而且非常有效,但是合理的确定K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响。众多的论文基于此都提出了各自行之有效的解决方案,新的改进算法仍然不断被提出,此类文章大家可以在Web Of Science中搜索。
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。
4.部分源码
clc;
clear;
close all;
warning off;
addpath(genpath(pwd));
[x1,x2,r1,r2,r3,r4]=data3();%读取数据
x=[x1;x2];
%随意设定俩初始聚类中心,采取K=2
u1=x1(1,:);
u2=x2(1,:);
for y=1:2000 %设置粗估循环多少次
[U1,U2] = count(u1,u2,x);%分类
[u1,u2,k] = new(U1,U2,u1,u2);%更新聚类中心
if k==1 %根据k值来判断循环是否结束
break;
end
end
%写出最终的聚类中心
u1
u2
A114